


Ready to build better conversations?
Simple to set up. Easy to use. Powerful integrations.
Get free accessReady to build better conversations?
Simple to set up. Easy to use. Powerful integrations.
Get free accessWhen we think about system reliability, the instinct is often to monitor all layers—from the top (DNS) down to the database itself. Every request passing through your infrastructure touches multiple layers, and ideally, each one should be observed and maintained. Yet, in practice, teams often focus primarily on the middle layer: the application.
For databases, monitoring usually revolves around metrics like slow queries, CPU consumption, memory usage, and storage. But there’s another, often underestimated aspect of database reliability: schema evolution. Over time, as features are added and requirements change, database schemas evolve, and ensuring this evolution happens safely is critical, but tricky.
Schema migrations: The hidden challenge
In our experience, database schema migrations are frequently overlooked, yet they can have a significant impact on stability and developer productivity. Uncoordinated or poorly tracked migrations can lead to inconsistencies, downtime, or even data loss.
To address this, we wanted to improve the developer experience around schema changes, acting as a kind of co-pilot to guide safe migrations.
One of the key challenges is drift detection. Just as we monitor infrastructure with tools like ArgoCD to detect when deployed resources diverge from their intended state, database schemas can drift from what our code expects. Detecting this early helps teams prevent issues before they reach production.
Inspired by Ariga: Treating schemas like code
We drew inspiration from the approach taken by Ariga: just as we lint, plan, and deploy Terraform configurations, we can apply the same principles to database schema migrations. This approach allows us to:
Enforce best practices consistently across all projects.
Track and version migrations to ensure predictable, auditable changes.
Provide developer feedback early in the development cycle, preventing errors before they reach production.
Two main features: Monitoring and migration directories
To put this approach into practice, we focused on two main pillars:
Monitoring: Observing schemas for drift, tracking query performance, and alerting teams on anomalies.
Migration directories: Structuring and standardizing migrations across projects, enabling us to extend best practices and maintain a reliable, consistent developer experience.
By combining monitoring with structured migrations, we can proactively maintain database reliability while improving developer efficiency. It’s like having a co-pilot for your database: you still fly the plane, but with an extra set of eyes watching the instruments.
Developer feedback in action
Here are three concrete examples of the feedback developers receive during their migration workflow:
NOT NULL constraints on existing data: If a developer tries to add a NOT NULL constraint to a column in a table that already contains data, Atlas immediately flags this as an error. Without this check, the migration would fail in production if any existing rows have null values in that column.
Creating indexes safely: When adding an index to a large table, Atlas enforces that the index must be created with the CONCURRENTLY option in PostgreSQL. Without this, the entire table could be locked during index creation, potentially causing application downtime. Atlas catches this before the migration ever reaches the database.
Blocking destructive operations: Atlas blocks destructive operations like DROP TABLE or DROP COLUMN entirely, requiring developers to explicitly acknowledge and override these changes. This prevents accidental data loss from slipping through code review unnoticed.
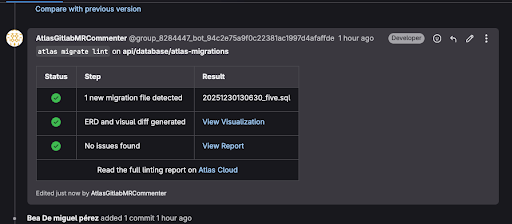
Looking ahead: Adopting AtlasGo
We’ve recently started adopting AtlasGo as part of this effort. The tool has been promising so far, helping us manage migrations, detect schema drift, and enforce best practices across projects.
While there’s still more to learn and refine, we’re excited about the potential to improve database reliability and developer experience. We plan to share more insights, lessons learned, and practical tips from our experience in the future. For now, it’s encouraging to see how structured monitoring and schema-as-code practices can make a real difference, and we’re happy to begin this journey.
If you’d like to hear more tips and stories from our team of innovators and developers, check out our full range of Tech Team Stories.
Published on April 28, 2026.
